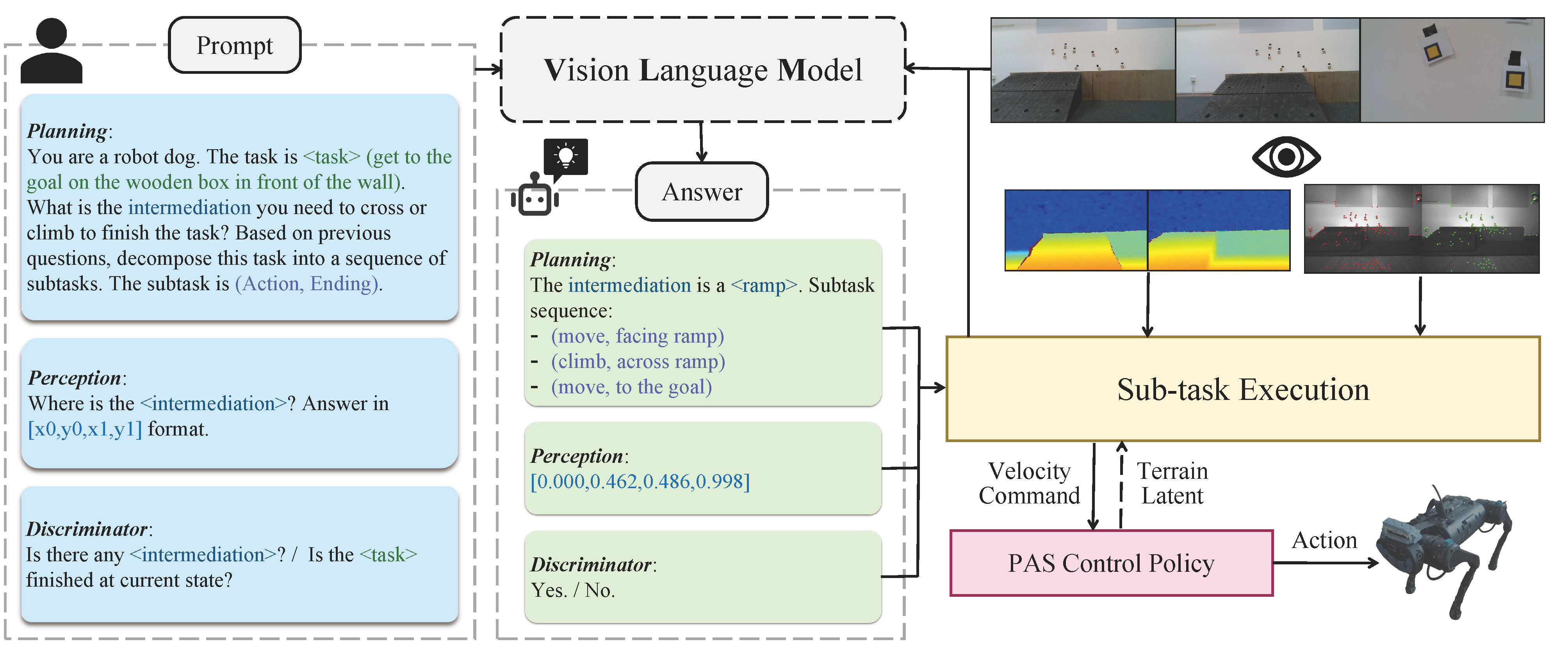
The application of vision-language models (VLMs) has achieved impressive success in various robotics tasks. However, there are few explorations for foundation models used in quadruped robot navigation through terrains in 3D environments. We introduce SARO (Space-Aware Robot System for Terrain Crossing), an innovative system composed of a high-level reasoning module, a closed-loop sub-task execution module, and a low-level control policy. It enables the robot to navigate across 3D terrains and reach the goal position. For high-level reasoning and execution, we propose a novel algorithmic system taking advantage of a VLM, with a design of task decomposition and a closed-loop sub-task execution mechanism. For low-level locomotion control, we utilize the Probability Annealing Selection (PAS) method to effectively train a control policy by reinforcement learning. Numerous experiments show that our whole system can accurately and robustly navigate across several 3D terrains, and its generalization ability ensures the applications in diverse indoor and outdoor scenarios and terrains.
SARO system is composed of a high-level reasoning module, a closed-loop sub-task execution module, and a low-level control policy. The robot needs to complete a goal-tracking task while autonomously navigating through a 3D terrain. The pretrained vision-language foundation model (VLM) takes as input RGB images and prompts querying the 3D environment perception to decompose the task into sub-tasks. After that, the system executes these sub-tasks in a closed-loop taking advantage of VLM discriminator double-check. The well-designed sub-task execution module connects the high-level VLM and the low-level control policy and receives depth image and stereo image information to help localization.
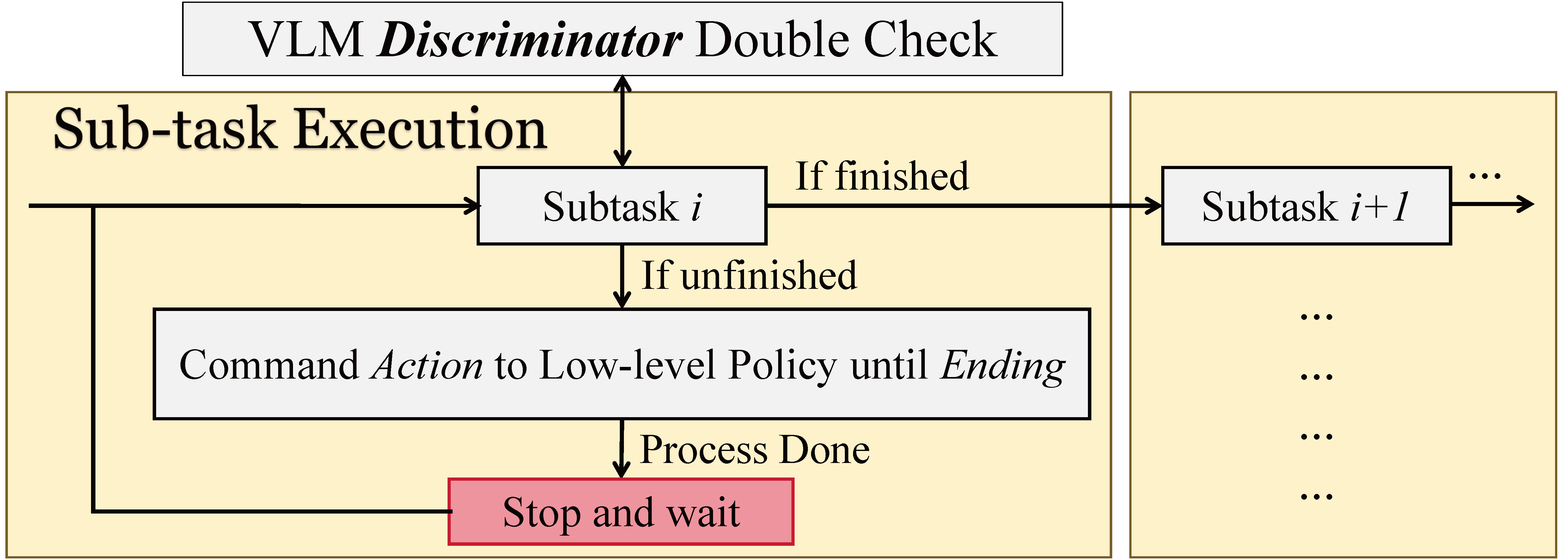
After task decomposition, the system executes the sub-tasks one by one. The double-check closed-loop module improves the robustness of the system.
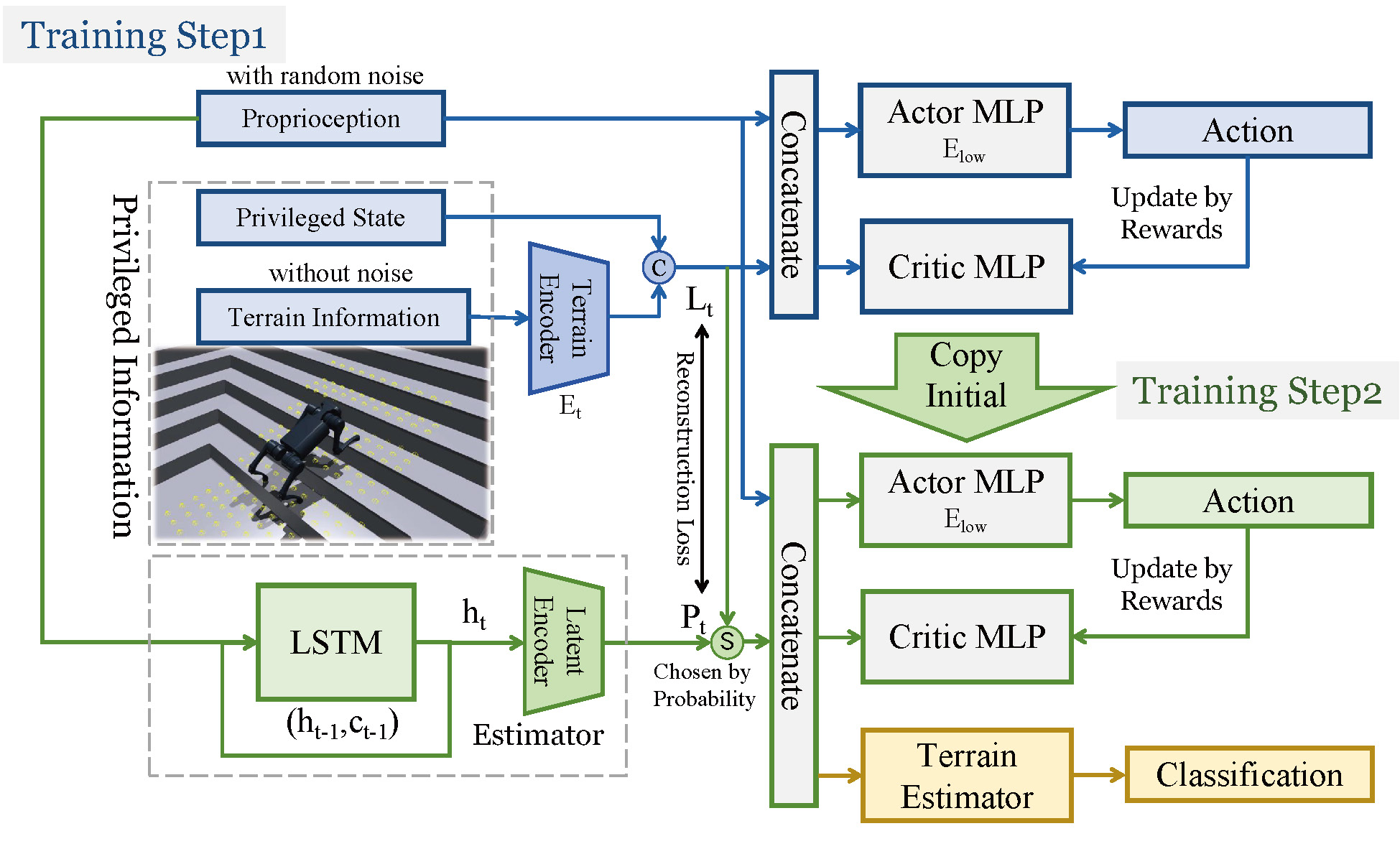
We conduct two-stage training paradigm to obtain robust low-level locomotion policy. In the first training step, we train an oracle policy using proprioception, privileged state, and terrain information. In the second training step, we use the probability annealing selection (PAS) method to train the final actor network, which only uses proprioception as input. After the policy training process is finished, we exclusively train a terrain estimator to classify whether the robot is on the plane or is climbing the intermediation.
To evaluate our crossing system, experiments are conducted based on versatile routes in the real world. We test the robustness on different terrains including stairs, ramps, gaps, and doors. For every terrain, the goals are at various directions.

Additionally, we test our system outdoors to show the generalizing ability. We spot that our framework can be easily extended to the wild environment and the versatile 3D terrain conditions can be covered by our robust perception, planning, and control pipeline.

@article{zhu2024saro,
title={SARO: Space-Aware Robot System for Terrain Crossing via Vision-Language Model},
author={Zhu, Shaoting and Li, Derun and Mou, Linzhan and Liu, Yong and Xu, Ningyi and Zhao, Hang},
journal={arXiv preprint arXiv:2407.16412},
year={2024}
}
